Composable Accelerator
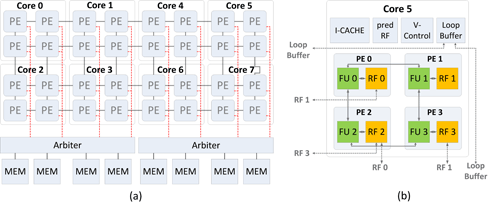
A Polymorphic Pipeline Array (PPA) is a composable accelerator for embedded systems that can exploit both the fine-grain parallelism found in innermost loops and the pipeline parallelism found in streaming applications. A PPA consists of multiple simple cores that are tightly coupled to neighboring cores in a mesh-style interconnect. There are a total of 32 processing elements (PEs) in 8-core PPA, each containing one function unit (FU) and a register file (RF). Four PEs are combined to create a core that can execute its own instruction stream. Each core has its own scratch pad memory and column buses connect 4 PEs to a memory access arbiter that provides sharing of scratch pad memories among the cores.
The major feature of the PPA is its ability to exploit both fine-grain and coarse-grain pipeline parallelism. Since each PPA core can process its own instruction stream, coarse-grain parallelism can be exploited for streaming applications. The communication between pipeline stages can be efficiently supported with DMA connections between cores. Abundant fine-grain parallelism within a pipeline stage can also be exploited by aggregating multiple cores to form a larger logical core allowing for maximized resource utilization. This is efficient since the PPA provides fast inter-core communication using a mesh-style interconnect.
PPA Overview: (a) PPA with 8 cores, (b) Inside a single PPA core
Partitioning Schemes
Static Partitioning
The PPA array can be partitioned statically based on the resource requirement of each
coarse-grain pipeline stage.
Static partitioning has its benefit in achieving high quality
schedules, but it cannot adapt to dynamically changing resource
availability.
When an application has a large variation
in execution pattern, static partitioning can either result in low
utilization of resources, or may not be able to fully accelerate the
application when there are not enough resources available.
Dynamic Partitioning
Coarse-grain pipeline stages in multimedia applications have different
execution patterns, resulting in fluctuating resource requirements.
Dynamic partitioning can come in handy with the presence of dynamic
variation of resource requirements. The partitioning of the PPA
array can change during runtime on demand. For a single pipeline
stage, a single core can be assigned to an acyclic region of
code, but more resources can be assigned to the compute intensive
loop kernels to exploit fine-grain parallelism.
Dynamic partitioning assumes the sharing of resources between
neighboring pipeline stages. The resources sitting idle in one
stage can be utilized by neighboring stages through resource borrowing.
So, it is not guaranteed that the required resource is available
at all times in dynamic partitioning.
When the required resource is not available, the stage stalls and waits
for the resource.
Virtualization can avoid stalls due to resource contention by
generating a schedule that can be modified easily at runtime to
run on different number of resources.
Compilation Challenges and Solution
Efficient scheduling for composable accelerators is now emerging as an interesting, and challenging problem due to the high degree of freedom in both the hardware and software. Some factors that make scheduling difficult are:
Resource Requirement Variance
The optimal resource requirement for
efficient parallelism depends on the task-specific characteristics. For
example, cyclic code regions can be accelerated efficiently by appropriating more
resources, but the performance of acyclic code with sequential dependences
cannot be improved by supplying additional resources.
Assuming worst-case requirements for all code segments leads to either
over-provisioned designs to achieve a desired performance or under-performance
for a fixed design.
Execution Time Variance
Composable accelerators typically have multiple tasks running in parallel,
and they usually have complex dependences.
Thus, it is hard to predict the resource usage pattern
and accommodate the optimal execution of multiple instruction streams.
Geometry
In CMPs, full connectivity between processors is
often provided. However, in a low-cost accelerator, the
interconnect is much more sparse and merging cores should be performed
in a connectivity-aware manner.
Static partitioning of the cores can potentially eliminate these problems, such as stalls and reconfiguration overhead. However, the workload of each core may not be balanced well because we categorized all the tasks based on optimum resource requirements. To minimize this side effect, a final performance tuning phase is performed using dynamic partitioning of cores. Additionally, we also propose a core reallocation mechanism to avoid geometry-based runtime overhead.
Relevant Publications
- None.
Page last modified January 22, 2016.