
With the advent of programmable GPUs, throughput oriented workloads are quickly moving onto these architectures. Workloads where throughput is more important than latency have shown tremendous performance on these architectures. The applications that have shown improvement on these programmable GPUs are data-parallel, floating point computation intensive, and dense matrix style applications. But these architectures are also very energy-inefficient. The power budget for such systems is already approaching 1KW per card. The plot below shows the performance per watt of architectures that have been used for throughput processing. As can be seen from the plot below, all architectures lie between 0.1Mops/mw to 10Mops/mw. Though power is not necessarily a significant drawback for GPUs now, futurisitic applications that will require more computations may have power acting as a serious impediment. Many projections already suggest that for a peta-flop of performance, thousands of kilo-watts will be required.
Efficiency of High Performance Computing
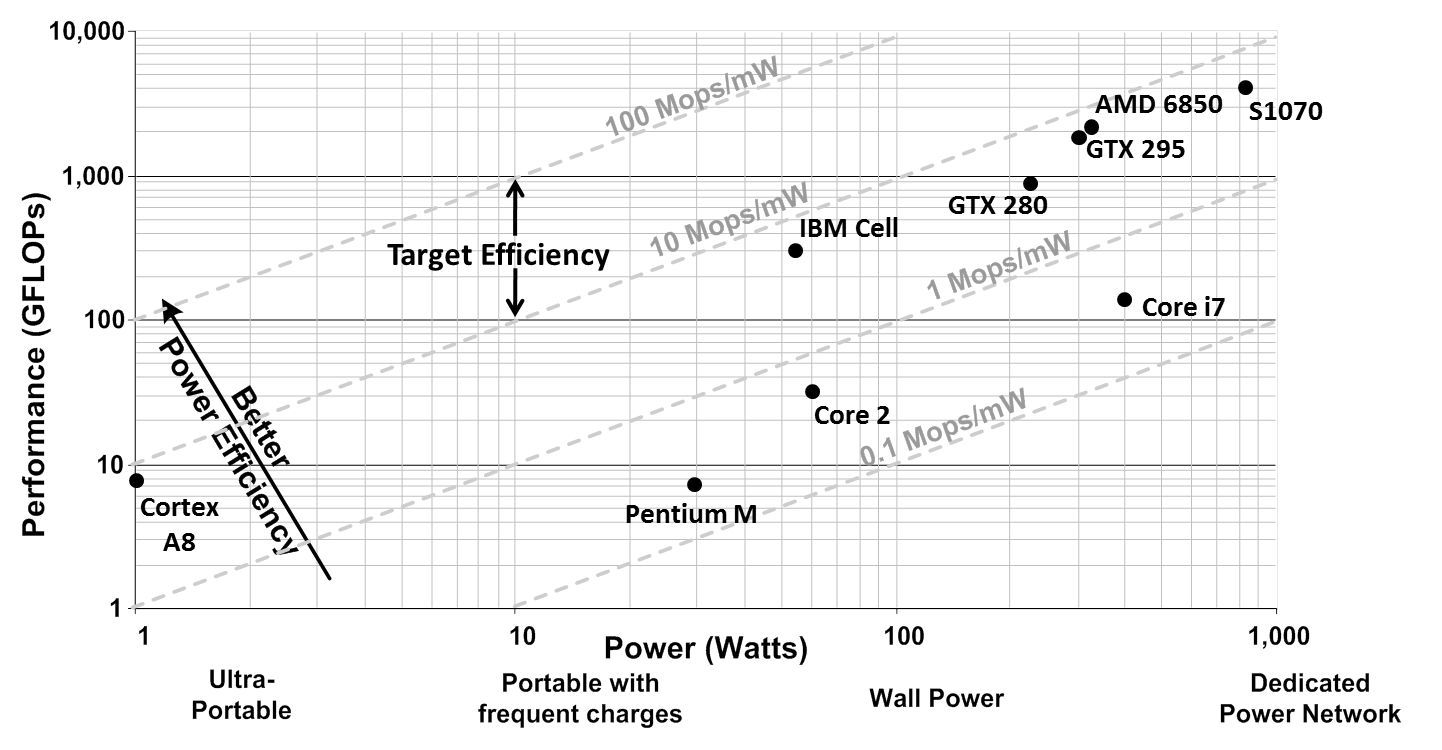
On the opposite of the spectrum is the case of smartphones. Their appetite for higher computation power has been increasing dramatically. But the nature of the device makes power/energy the biggest challenge. With newer and richer "apps" coming out everyday, the architectures of the processors on these cores is changing at a rapid pace. So what we are observing here is a convergence between scientific processing and processing on smartphone where power is the first-class challenge. The goal of this work is to come up with architecture designs which will lie at a higher efficiency than current architectures.
Our work on throughput processor design focusses on investigating architectural designs and techniques that can provide higher energy efficiency by better utilization of the hardware as compared to the current best GPU solutions. We are looking at workloads which have the above mentioned characteristics. These include both scientific and graphics applications. One solution is to develop ASICs or hardwired accelerators for common computation patterns. However we believe that this approach is orthogonal and focus on developing a fully programmable processor design for throughput computing.
Below is a list of some of the research we are (or have been) working on in the area of processors.
- Throughput Processing: GPUs do not necessarily get high utilization on their architecture. This work exposes their energy-inefficiency and proposes solutions to mitigate the causes of low-utilizations. A variety of novel architectural techniques have been put together to improve utilization for scientific computing. The current work shifts focus to increasing utilization of GPUs for graphics kernels.
- Composite Cores: is an architecture that allows reduced switching overheads between heterogenous cores by bringing the notion of heterogeneity within a single core. This architecture saves energy by enabling fine-grained switching between a high performance out-of-order pipeline and an energy efficient in-order pipeline.
- Software Defined Radio: The operation throughput requirements of third generation (3G) wireless protocols are already an order of magnitude higher than the capabilities of modern DSP processors, a gap that is likely to grow in the future. The SODA architecture provides a new architecture for these applications
- Speech Recognition: Speech recognition is characterized by a large number of independent threads and a poor memory performance, owing to the large overall footprint of the speech knowledge base and the highly input-dependent nature of the search process. These characteristics make modern processor architectures relatively unsuitable for running speech recognition, particularly on mobile computing platforms. Our approach is to exploit thread-level concurrency to create a low-power, high-performance architecture customized for speech recognition.
- Past Projects: Here you can find a list of our past projects in this domain.
Page last modified January 22, 2016.