
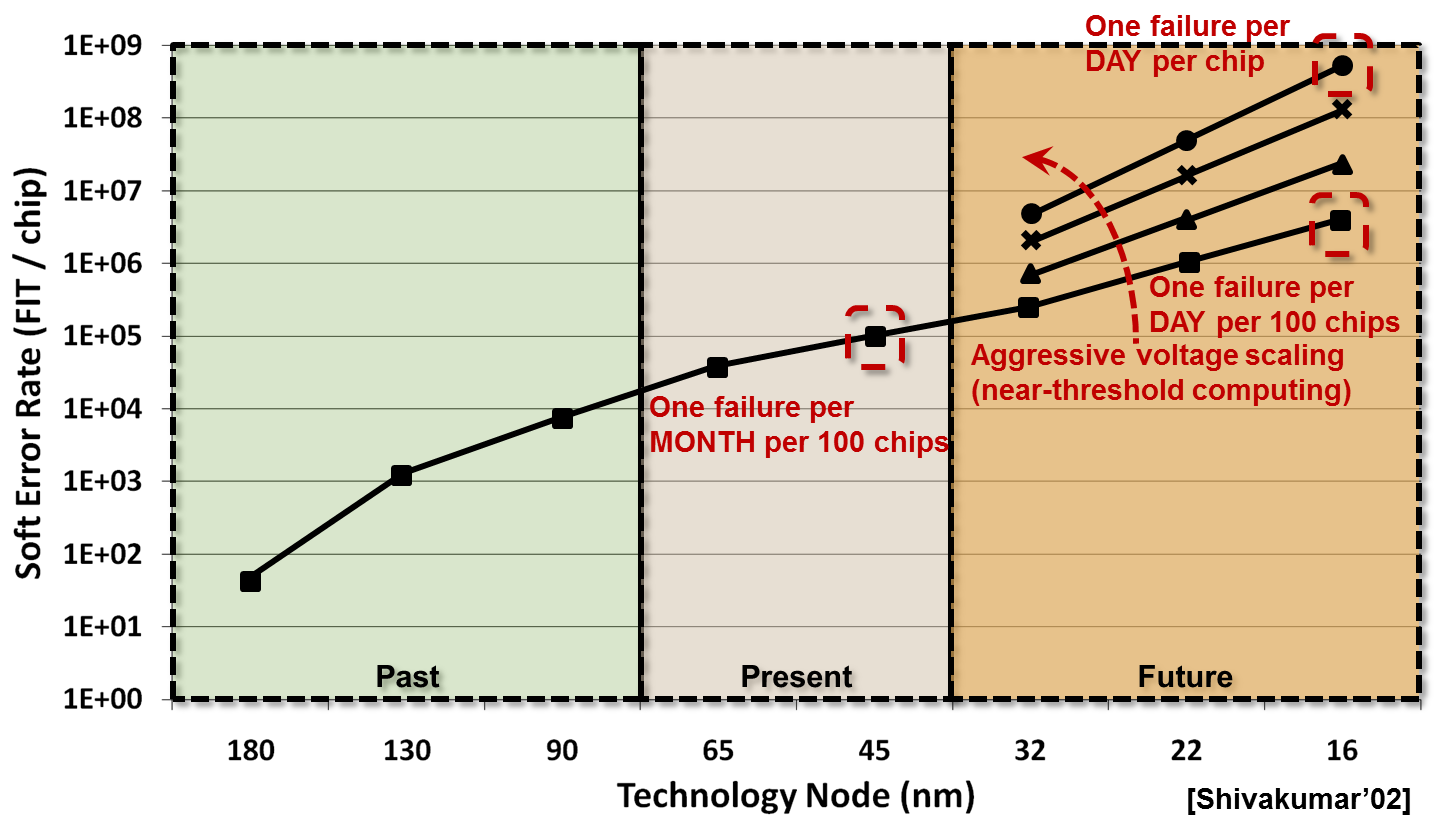
A critical aspect of any computer system is its reliability. Aggressive technology scaling in future computers provides designers with an ever increasing budget of cheaper and faster transistors. Unfortunately, this trend is accompanied by a decline in individual device reliability as transistors become increasingly susceptible to soft errors. We are quickly approaching a new era where resilience to soft errors is no longer a luxury that can be reserved for just processors in high-reliability, mission-critical domains. Even processors used in mainstream computing will soon require protection. However, due to tighter profit margins, reliable operation for these devices must come at little or no cost. A soft error, or transient fault, can be induced by electrical noise or high-energy particle strikes that result from cosmic radiation and chip packaging impurities. Unlike manufacturing or design defects which are persistent, transient faults only sporadically influence program execution. See the below Figure for an idea of how aggresive technology scaling can affect the soft error rate.
Another class of faults is hard faults. Hard-faults are permanent failure of device(s) in manufacuted components. Future microprocessors will contain of billions of transistors, many of which will be dead-on-arrival. Those that survive will be subjected to the effects of numerous wearout mechanisms such as time-dependent dielectric breakdown (TDDB), hot carrier injection (HCI), electromigration (EM), and negative bias temperature instability (NBTI.), which result in performance degradation and eventual device failure.
The goal of reliability research in this group is to provide cheaper and efficient software or architectural solutions for commodity market segment to tackle the problem of hard and soft errors.
Current Projects include an expansion of Shoestring and Encore. Both of these ideas were addressed initally by S. Feng of UMich, and Daya S Khudia and Griffin Wright are currently working to enhance fault detection and recovery, and to do so not as a backend compiler implementation but as an IR-level implementation.
Past Projects have included Maestro(pdf), StageNet and work with reliable caches done by Amin Ansari. See the list below for his works as well as other relevant reliablility publications by the CCCP.
Relevant Publications
- None.
Page last modified January 22, 2016.