
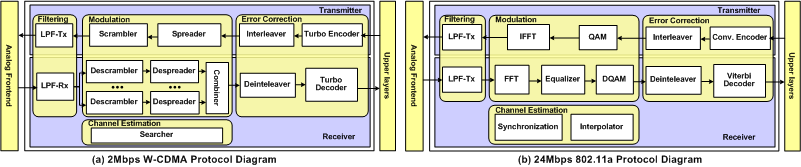
We use two representative, but very different, wireless protocols to understand the architectural requirements of physical layer signal processing for SDR. Wideband code division multiple access (W-CDMA) is one of the most common third generation cellular protocols. 802.11a is a standard wireless local area network (WLAN) protocol. We chose these two benchmarks since they are sufficiently different from each other algorithmically and are representative of the large spectrum of algorithms that need to be supported by an SDR platform. Both protocols have complex inter- and intra-algorithm interactions and behaviors. Above figures show the overall block diagrams of W-CDMA and 802.11a (including each DSP algorithm's vector width and data precision). Here we summarize our key observations into two categories: protocol system-level behavior and DSP algorithm-level behavior.
System level: DSP kernel macro-pipelining -- Wireless protocols usually consist of multiple DSP algorithm kernels connected together in feed-forward pipelines. Data is streamed through kernels sequentially.
System level: heterogeneous inter-kernel communications -- Some inter-kernel communications can be streamed, where the receiving kernel can process input data individually (e.g. filters). Other inter-kernel communications must be buffered, as the receiving kernels require blocks of the data (e.g. the interleaver and Turbo decoder).
System level: real-time deadlines -- All wireless protocols have real-time deadlines. Meeting these deadlines is one of the challenges that has received scant attention in previous DSP architectural studies. Meeting real-time deadlines requires concurrent execution management for multiple DSP algorithms.
Algorithm level: high data-level parallelism -- Most of the computationally intensive DSP algorithms have abundant data level parallelism. The heaviest workloads of the W-CDMA and 802.11a protocols, including the searcher, LPF, FFT, and Viterbi decoder, all operate on very wide vectors.
Algorithm level: 8- to 16-bit data width -- Most algorithms operate on variables with small values. Our analysis of W-CDMA and 802.11a suggests that the architecture should provide strong support for 8- and 16-bit fixed point operations. 32 bit fixed point and floating point support are not necessary. W-CDMA's algorithms mostly operate on 8-bit data, whereas 802.11a's algorithms mostly operate on 16-bit data.
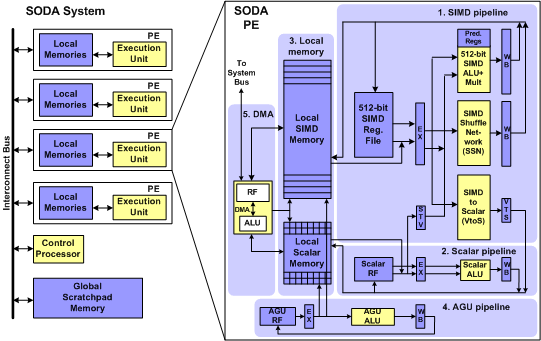
The SODA multiprocessor architecture is shown here. It consists of multiple processing elements (PEs), a scalar control processor, and global scratchpad memory, all connected through a shared bus. Each SODA PE consists of 5 major components:
1) SIMD (Single Instruction, Multiple Data) pipeline for supporting vector operations. The SIMD pipeline consists of a 32-way 16-bit datapath, with 32 arithmetic units working in lock-step. It is designed to handle computationally intensive DSP algorithms. Each datapath includes a 2 read-port, 1 write-port 16 entry register file, and one 16-bit ALU with multiplier.
2) Scalar pipeline for sequential operations. It is designed to handle the scalar workloads in DSP algorithms. It consists of one 16-bit datapath with 2 read-port, 1 write-port 16 entry register file. Data are transferred between the SIMD and scalar pipeline through STV and VTS registers.
3) Two local scratchpad memories for the SIMD pipeline and the scalar pipeline. Data is streamed through SDR kernels sequentially, resulting in almost no temporal locality. Thus cache structures provide little additional benefits, in terms of power and performance, over software controlled scratchpad memories.
4) AGU pipeline for providing the addresses for local memory access. The SIMD pipeline, scalar pipeline and the AGU pipeline execute in VLIW-styled lock-step, controlled with one program counter (PC).
5) Programmable DMA unit to transfer data between memories and interface with the outside system. The DMA unit has its own PC, its main purpose is to perform memory transfers and data rearrangement. It is also the only unit that can initiate memory access with the global scratchpad memory.
Relevant Publications
Page last modified January 22, 2016.