
Ten benchmarks from domains like communications, signal processing, mathematical modelling, finance etc. were analyzed. The source code for these applications is derived from a variety of sources, including the Nvidia CUDA software development kit, the GPGPU-SIM benchmark suite, the Rodinia benchmark suite, the Parboil benchmark suite, and the Nvidia CUDA Zone. We analyze the benchmarks' behavior on GPUs using the GPGPU-SIM simulator. The configuration used closely matches the Nvidia FX5800 configuration and is provided by their simulator. Modifications were made to make the simulated design very similar to the GTX 285 GPU, the most recent GPU that uses the FX5800's microarchitecture.
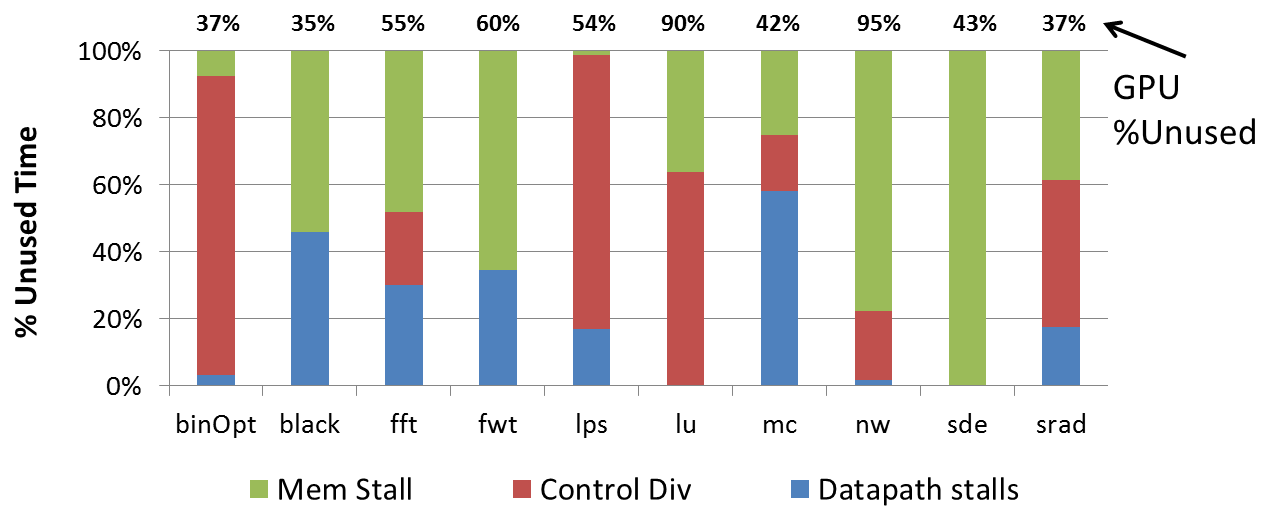
On average, these applications make use of around 45% of the GPU compute power, with the extremes being BlackScholes, with a 65% utilization, and Needleman-Wunsch, with a 5% utilization. It is important to note here that the utilizations of individual benchmarks vary widely. Further, the extent to which specific causes lead to underutilization also varies from one application to another. Above figure illustrates three principal reasons for underutilization in GPUs:
Datapath stalls: This portion of the graph indicates the amount of time the shader core datapath itself is stalled for reasons such as read-after-write hazards. This is especially of concern on GPUs, which tend to have very deep floating-point pipelines.
Memory stalls: The benefit from having numerous thread contexts in GPUs is the ability to hide memory latency by issuing a different thread-warp from the same block of instructions when one warp is waiting on memory. This is not always enough, however, and this portion of the graph indicates the amount of time that all available warps are waiting for data from memory. To check whether it is memory bandwidth or memory latency that is the limiting factor, a separate study was done using a machine configuration that had double the bandwidth of the GTX 285. The change in utilization was negligible.
Serialization: The CUDA system collects 32 individual threads into a ``warp'' and executes them in a manner similar to a 32-wide SIMD machine. In sequential code, threads in a warp all execute the same series of instructions. However, in the event that some threads take a different execution path, the warp is split into the taken and not-taken portions and these two newly-formed warps are executed back-to-back rather than concurrently, reducing the overall utilization of the processor. The ``control divergence'' portion of the graph indicates the amount of time that is spent executing fractions of a warp rather than an entire warp at a given time.
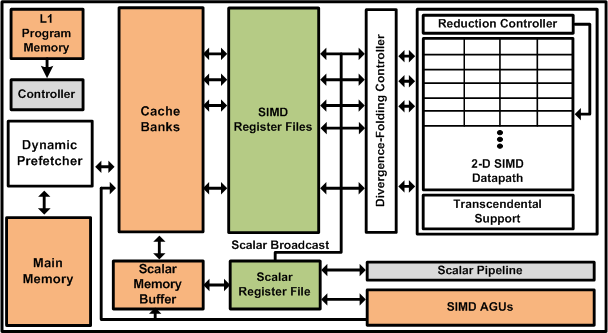
The PEPSC multiprocessor architecture is shown here. It builds on top of a baseline SIMD architecture by adding components such as 2-D SIMD Datapath, Divergence Folding Controller and a Dynamic Prefetcher.
1) SIMD Datapath: An optimized two-dimensional SIMD datapath design which leverages the power-efficiency of data-parallel architectures and aggressively fused floating-point units (FPUs).
2) Dynamic Degree Prefetcher: A more efficient method to hide large memory latency is described which does not exacerbate the memory bandwidth requirements of the application.
3) Divergence-folding: An architectural design integrated into the floating-point (FP) datapath to reduce the cost of control divergence in wide SIMD datapaths and exploit "branch-level" parallelism.
Relevant Publications
Page last modified January 22, 2016.