
Speech recognition is the task of translating an acoustic waveform representing human speech into its corresponding textual representation. This task is complicated by natural variations in spoken language that are difficult to handle in discrete systems. Examples include variations in intonation and accent (acoustic level), and variations in meaning such as the difference between "there" and "their" (linguistic level). Accommodating this flexibility requires the use of probabilistic modeling techniques.
Our speech recognition work is based on the CMU Sphinx system. Sphinx utilizes probabilistic Gaussian models of pre-trained phonetic sequence to score each discrete unit of speech against its knowledge base data. It then applies these scores to a phonetic/linguistic model of English language constructions represented as a Hidden Markov Model (HMM), producing a set of potential recognition hypotheses. The recognition hypothesis with the highest overall probability is presented as the final result.
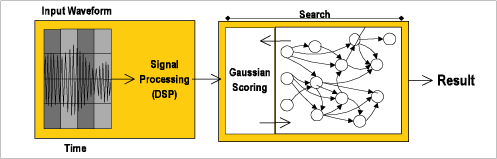
Speech recognition consists of two major steps (shown below). First, DSP-style operations such as A/D conversion and extraction of key feature vectors are performed. The resulting feature vectors are passed into a search phase, which involves Gaussian probabilistic scoring and linguistic model search tree traversal. The majority of the time and complexity of this process is the search phase. Independent hypotheses are explored during the search phase to determine an overall score for each. The search phase is characterized by high-thread level concurrency with hundreds to thousands of independent threads during a given iteration of the search algorithm. Due to the nature of stochastic search, the threads places high demands on the memory system and demonstrate both poor locality and predictability of access.
Overview of Steps in Speech Recognition
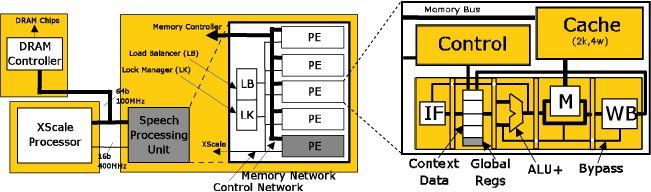
Our approach is to exploit thread-level concurrency to create a low-power, high-performance architecture customized for speech recognition. Parallelism is exploited across multiple processing elements as well as multiple threads within each element to effectively deal with memory latency. The system (shown below) is based on a standard Intel XScale processor with a series of instruction set extensions to control the speech processing unit. The speech processing unit is made up of a number of simple in-order integer pipelines, each with multiple hardware thread contexts. Each pipeline utilizes a small data cache to capture data actively under evaluation. The search phase of the Sphinx system is distributed across the processing elements using a combination of static workload partitioning and dynamic load balancing. Approximately 92% of the search phase code is executed in parallel on the speech coprocessor.
Speech Processing System Architecture
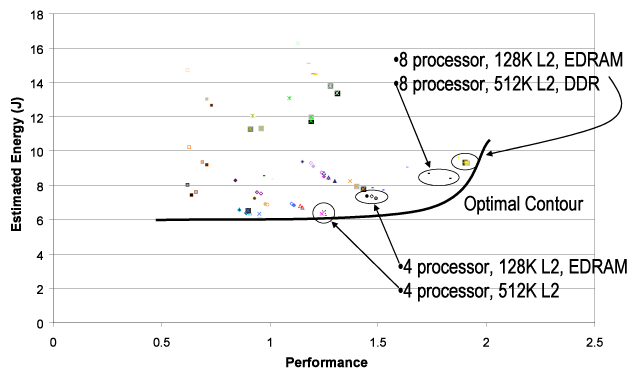
The graph below presents the set of Pareto designs (energy versus performance) for the set of speech processing unit designs that we have currently explored. Performance is expressed as a fraction of real-time performance. To this point, the following conclusions have been reached regarding the system:
- Idealized performance - With an idealized memory subsystem (fixed latency and unlimited bandwidth), near ideal speedups are achieved as the system is scaled with more processing elements. Higher memory latencies can be mitigated with additional thread contexts to essentially hide the delay by performing other useful work.
- Memory wall - When the idealized memory system is converted to a real, SDRAM-only system, performance suffers dramatically with almost all speedups observed in the idealized case lost. Bandwidth and request rate limitations are the major source of the problem.
- Cache metadata - While the program knowledge base data generally demonstrates low locality, metadata and data elements currently under evaluation showing significant caching opportunities. Small L1 caches and a large shared L2 are effective at achieving this objective. Further, they significantly offload some of the bandwidth requirements for the underlying DRAM system.
- DDR vs SDRAM - Faster memory subsystems can improve performance modestly, but the energy overhead is not justified. The speech processing unit is highly capable of tolerating memory latency, thus lower power (and slower) memories are more effective.
Performance vs Energy Pareto Designs
Relevant Publications
Page last modified January 22, 2016.