Maestro
As CMOS feature sizes venture deep into the nanometer regime,
wearout mechanisms including negative-bias temperature instability and timedependent
dielectric breakdown can severely reduce processor operating lifetimes
and performance. This paper presents an introspective reliability management
system, Maestro, to tackle reliability challenges in future chip multiprocessors
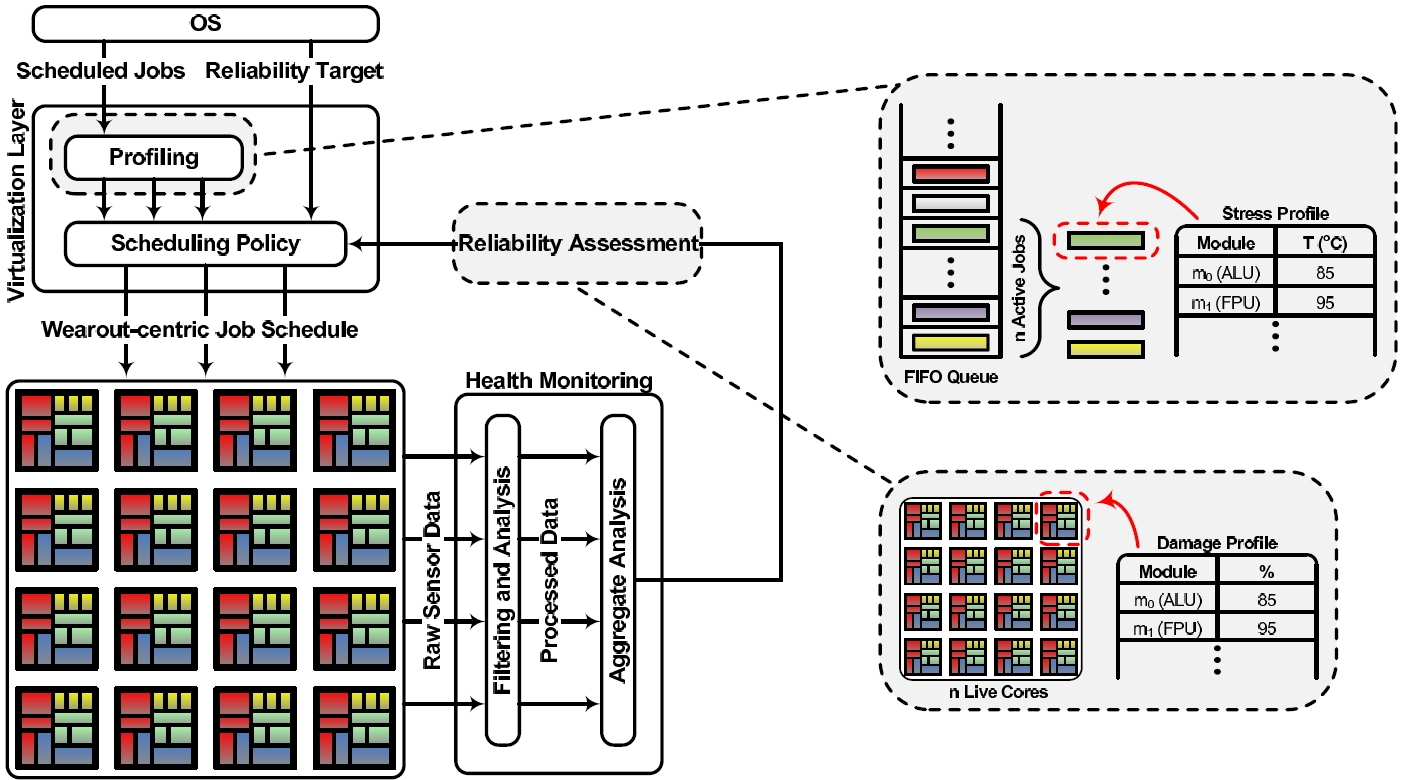
(CMPs) head-on. Unlike traditional approaches, Maestro relies on low-level sensors
to monitor the CMP as it ages (introspection). Leveraging this real-time
assessment of CMP health, runtime heuristics identify wearout-centric job assignments
(management). By exploiting the complementary effects of the natural
heterogeneity (due to process variation and wearout) that exists in CMPs and the
diversity found in system workloads, Maestro composes job schedules that intelligently
control the aging process. Monte Carlo experiments show that Maestro
significantly enhances lifetime reliability through intelligent wear-leveling, increasing
the expected service life of a population of 16-core CMPs by as much as
38% compared to a naive, round-robin scheduler. Furthermore, in the presence of
process variation, Maestro's wearout-centric scheduling outperformed both performance
counter and temperature sensor based schedulers, achieving an order
of magnitude more improvement in lifetime throughput -- the amount of useful
work done by a system prior to failure.
Read the Maestro paper here: pdf
StageNet
The goal of this work is to design a robust and scalable multithreaded system. To ensure reliable operation, the system is designed to be both introspective and reconfigurable. Introspection enables the system to accurately detect and diagnose transient faults, which may be caused by particle strikes, excessive temperature densities, or electrical noise. Component failures due to wearout phenomenon, such as electromigration and dielectric breakdown, can also be anticipated by an effective introspection scheme. Fine-grained reconfigurability maximizes the lifetime of the system and allows it to adapt to changing conditions on the chip. The adaptive capabilities of the system allow it to maintain service in the face of failing components. Further, this system is designed with a large number of redundant structures which gives it the flexibility of supporting multiple threads when appropriate to maximize performance or as structures fail, to reduce throughput and gracefully degrade over time.
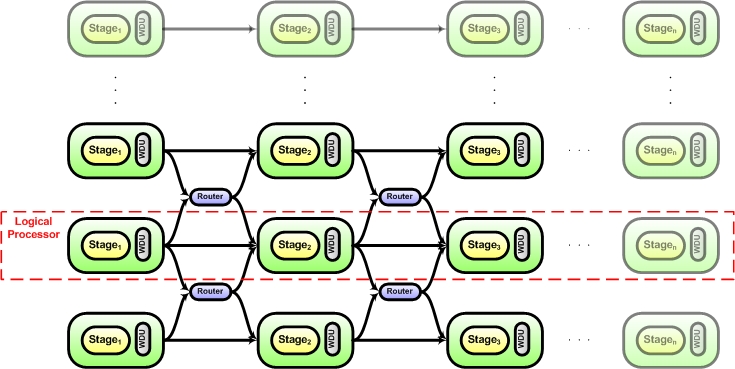
Processor cores within the proposed system are designed as part of a network-on-chip, where each stage in a coarse-grained processor pipeline corresponds to a node in the network. Pipeline stages are then replicated and grouped together to create multiple logical processors. The interconnect between these pipeline stages is designed to be flexible so that the system can react to local phenomenon. Multiple nodes may be allocated temporarily to a single thread to exploit instruction level parallelism, while at other times the system may evenly distribute resources between all of the logical processors in order to maximize throughput. Similarly, the system can temporarily arrest allocation of nodes that are excessively hot, as well as retire nodes that are deemed defective. As nodes wear out and eventually fail, throughput gradually decreases and performance gracefully degrades.
Read the StageNet paper here: pdf
Page last modified January 22, 2016.