
Designers seeking energy efficient solutions in the past have typically targetted embedded systems by developing application specific hardware and accelerators. Unfortunately, these approaches do not extend to general purpose applications due to their irregular and diverse code base. BERET is a energy-efficient co-processor that targets general purpose programs while also offering the flexability to work across multiple applications. BERET is able to reduce energy consumption while maintaining performance by using Bundled Execution of REcurring Traces. BERET relies on accelerating recurring instruction traces (loops) to cut down on redundant instruction fetch and decode energy, and uses bundled (or chained) execution units to reduce register reads and writes for temporary variables.
Bundled Execution
Traditional processors spend a large amount of energy reading and writing to the register file. In a hot (or frequently executed) loop, many of these writes are immediatly read by the following instruction and never used again. When this occurs, the energy spent writing the value to the register file is essentially wasted as the value is no longer needed. One approach to minimize this energy loss is to create complex instructions that can perform multiple independent actions using temporary buffers within the functional units. By creating small chained operations, we can recover the energy that would otherwise be wasted with a write/read sequence to the register file. If these chains are composed of frequently executed patterns, we can not only register read/write energy we can also minimize the fetch/decode energy that would be spent on the simple instructions.
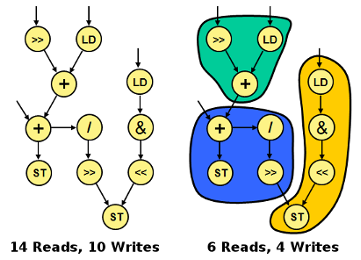
Recurring Traces
Typical loops in general purpose programs are irregular, meaning they are large and control intensive. Use profiling, a compiler can isolate the most common path through a loop, and convert all other exits to asserts. Now if we look at the hot trace, we are left with only straight line code with a single loopback branch, which can be executed on much simpler hardware. As these hot traces are typically short, they can be predecoded and fit in a small configuration RAM. We can then map these hot loops to a Subgraph Execution Block (SEB) on the BERET architecture, which offers significant instruction fetch and decode savings as the loop's instructions are stored predecoded in the Configuration RAM.
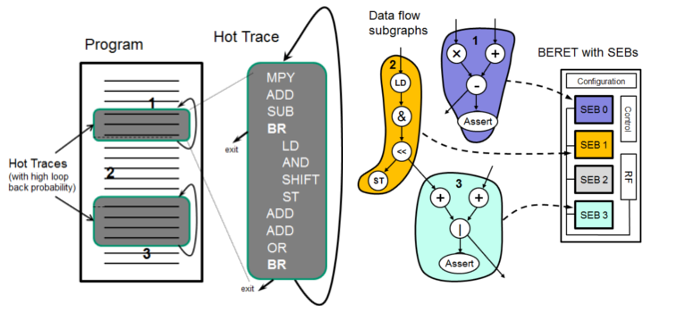
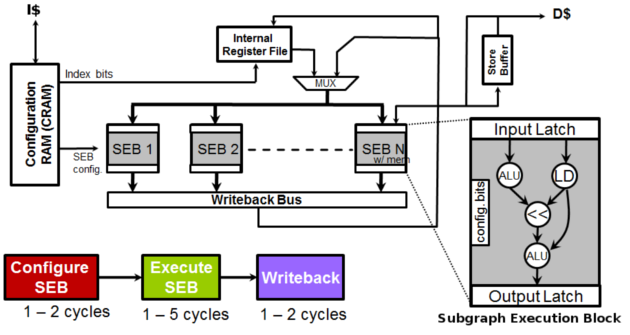
BERET architecture
The BERET system consists of multiple Subgraph Execution Blocks that are connected to an internal register file. Each of the SEBs is capabile of executing a different chain of bunded instructions. All of the SEBs are connected to an internal register file, and one of the SEB's is cabaple of performing load and store operations. When the main processor encounters a hot loop, control is transfered to the BERET processor which loads the current context into the internal register file and the pre-decoded instructions into the Configuration RAM (CRAM). The CRAM then controls when and which SEB's are active to perform the hot loop, and monitors for asserts indicating a side exit. When a side exit is taken, the internal register file's contents and control are transfered back to the main processor.
Relevant Publications
Page last modified January 22, 2016.