
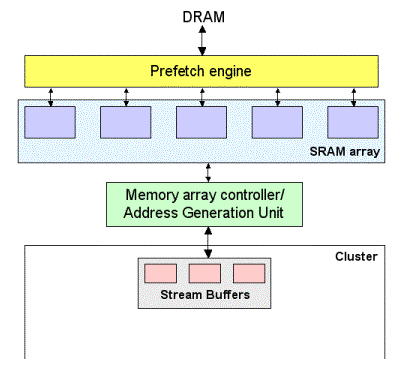
One characteristic of many embedded applications is that large amounts of data are accessed. High bandwidth and fast accesses are required to achieve the desired performance levels. These objectives cannot be achieved by using large, centralized, multi-ported memory structures, though. Such designs are far too costly and often ineffective due to their complex designs and large access latencies. Distributed local memories (or scratchpads) offer the possibility of achieving the desired data processing rates and access latencies at large cost and power savings. An application's Data is distributed across a set of local memories that are placed near the computation elements that require the data. High bandwidth is achieved by accessing the memory structures in parallel. Low latency is achieved by keeping the memories small and by grouping the memory structures with the function units that require the data and restricting communications to geographic proximities.
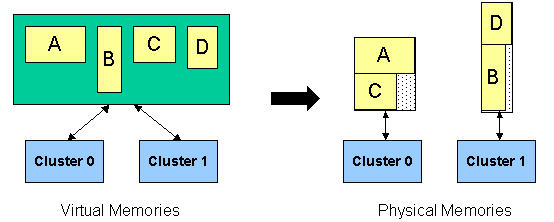
Several interrelated problems must be solved to synthesize a customized memory organization: the number, size, and porting of local memories; the location of the local memories within a clustered architecture; and partitioning data for distribution across local memories. To this end, we have proposed a solution to synthesize custom data memories for loop accelerators.
Our approach to synthesizing custom memories for loop accelerators is to break the complex problem into simpler sub-problems that are solved in a phase-ordered manner: pre-partitioning, memory synthesis, and partitioning. Initially, each data structure (array or scalar) is placed into its own virtual local memory that has no FU access restrictions. A performance-centric dataflow graph partitioning phase is done to pre-partition operations, including the virtual memory accesses, to datapath clusters. Memory synthesis is performed on the prebound memory accesses, combining virtual local memories to form a set of physical memories for each cluster. Finally, a second partitioning phase assigns operations to clusters with a fixed local memory organization to create the final specification of the architecture for the ASIC (or assembly code for the ASIP).
Relevant Publications
Page last modified January 22, 2016.