
Instruction set customization is common method for providing enhanced performance in processors. By creating application-specific extensions to an instruction set, the critical portions of an application's dataflow graph (DFG) can be accelerated by mapping them to specialized hardware. Instruction set extensions improve performance and reduce energy consumption of processors. They also maintain a degree of system programmability, which enables them to be utilized with more flexibility. An additional benefit is that automation techniques, such as the ones used by ARM OptimoDE, Tensilica, and ARC, have been developed to allow the use of instruction set extensions without undue burden on hardware and software designers.
The main problem with application specific instruction set extensions is that there are significant non-recurring engineering costs associated with implementing them. The addition of instruction set extensions to a baseline processor brings along with it many of the issues associated with designing a brand new processor in the first place. For example, a new set of masks must be created to fabricate the chip, the chip must be reverified (using both functional and timing verification), and the new instructions must fit into a previously established pipeline timing model. Furthermore, extensions designed for one domain are often not useful in another, due to the diversity of computation causing the extensions to have only limited applicability.
An example CCA. Light blue boxes support bitwise operations,
while dark blue boxes support bitwise and arithmetic operations.
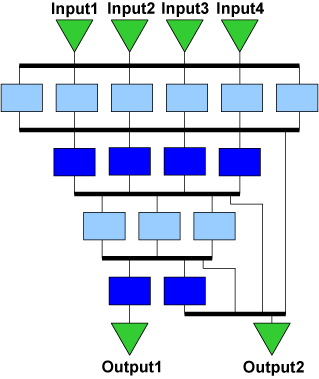
To overcome these problems, this research focuses on a strategy to customize the computation capabilities of a processor within the context of a general-purpose instruction set, referred to as transparent instruction set customization. The goal is to extract many of the benefits of traditional instruction set customization without having to break open the processor design each time. This is achieved by adding a configurable compute accelerator (CCA) to the baseline processor design that provides the functionality of a wide range of application-specific instruction set extensions in a single hardware unit. The CCA consists of an array of function units that can efficiently implement many common dataflow subgraphs. Subgraphs are identified to be offloaded to the CCA and then replaced with microarchitectural instructions that configure and utilize the array.
This design was found to be very effective at providing speedup for a wide range of applications.
An alternate accelerator design, the PCFU
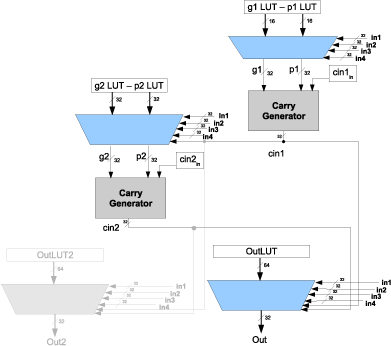
An alternate accelerator design, called the Programmable-Carry Function Unit (PCFU), was developed in conjunction researchers from ARM. The PCFU is a parameterized lookup table (LUT) based accelerator, similar to an FPGA. However, the PCFU leverages the design of carry lookahead adders to break the cascaded tree of LUTs, which is a weakness in many FPGA-style accelerators. This creates a faster and more efficient design. With an underlying lookup table structure, the PCFU is completely configurable and can execute a larger variety of arithmetic subgraphs than the CCA. Our publications have explored the tradeoffs associated with each design.
Methods that utilize these accelerators transparently are discussed in the Accelerator Virtualization page.
Relevant Publications
Page last modified January 22, 2016.