
Traditionally, when adding accelerators to a processor, architects will explicitly expose them through the instuction set. This is a problem because there are significant non-recurring engineering costs associated with this. The addition of instruction set extensions to a baseline processor brings along with it many of the issues associated with designing a brand new processor. For example, a new set of masks must be created to fabricate the chip, the chip must be reverified (using both functional and timing verification), and the new instructions must fit into a previously established pipeline timing model. Furthermore, extensions designed for one domain are often not useful in another, due to the diversity of computation causing the extensions to have only limited applicability.
The objective of our accelerator virtualization work is to separate the accelerator implementation from the ISA, providing an abstraction to overcome ISA migration problems. Accelerator virtualization offers a number of important advantages for families of processor implementations. First, accelerators can be deployed without having to alter the instruction set and introduce ISA compatibility problems. These problems are prohibitively expensive for many practical purposes. Second, virtualization allows an application to be developed for one accelerator, but be utilized by completely different accelerators (e.g., an older or newer generation accelerator). This eases non-recurring engineering costs in evolving accelerators or enables companies to differentiate processors based on acceleration capabilities provided. Finally, code that targets accelerators in a virtualized manner can be run on processors with no accelerator, simply by using native scalar instructions.
Several different strategies are proposed for accomplishing accelerator vitualization. One strategy, a fully dynamic scheme, performs subgraph identification and instruction replacement in hardware. This technique is effective for preexisting program binaries. To reduce hardware complexity, a hybrid static-dynamic strategy is also proposed, which performs subgraph identification offline during the compilation process. Subgraphs that are to be mapped onto the accelerator are marked in the program binary to facilitate simple configuration and replacement at run-time by the hardware.
Example pipeline designed to support virtualization for the
CCA
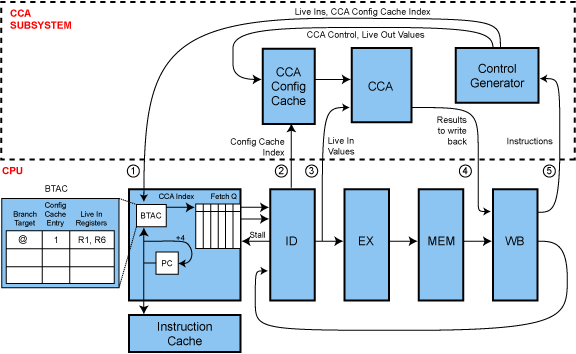
As an example of how accelerator virtualization is realized, a pipeline designed for static identification-dynamic replacement targeting the CCA is shown above. The baseline processor, at the bottom of the figure, is augmented with the CCA subsystem at the top of the figure. The CCA subsystem consists of three major parts: the CCA itself, a configuration cache, and a control generator. The control generator is responsible for examining a sequence of retiring instructions and determining the required control signals for the CCA. Each entry of the configuration cache specifies the necessary control signals for configuring the CCA, including the opcode implemented on each CCA function unit, the interconnect between function units, and any literal values used by the subgraph.
The core processor is augmented in several places to interact with the CCA. Changes primarily occur in the instruction fetch stage of the pipeline, where instruction stream substitution occurs. The branch target address cache, or BTAC (sometimes called BTB in other literature), is extended to store additional information to decide when it is possible to substitute a CCA instruction for an invocation of an accelerated subgraph. To accomplish this, a CCA configuration cache entry and register indexes for values consumed by the subgraph are included in the BTAC. The decode and writeback stages are also modified to provide register inputs and accept register results from the CCA.
Central to the virtualization framework is a well-defined interface between the core and the CCA subsystem. The interface is designed so that the core can use multiple CCA designs. Since any hardware placed on the CCA subsystem increases the cost of customization, the necessary structures were integrated into the main pipeline as much as possible while maintaining the flexibility of the interface.
In our HPCA 2007 paper, this basic design was extended to support virtualization of SIMD accelerators.
Relevant Publications
Page last modified January 22, 2016.