
With the proliferation of cellular phones, digital cameras, PDAs, and other portable computing systems, power consumption in microprocessors has become a dominant design concern. Power consumption directly affects both battery lifetime and the amount of heat that must be dissipated, thus it is critical to create power-efficient designs. However, many of these devices perform computationally demanding processing of images, sound, video, or packet streams. Thus, simply scaling voltage/frequency to reduce power is insufficient as the desired performance level cannot be achieved. Hardware and software solutions that maintain performance while reducing power consumption are required.
It is well known that the memory sub-system is responsible for a significant percentage of the overall power dissipation. For example, in the StrongARM-110 and the Motorola MCORE, the memory sub-system consumes more than 40\% of the overall system power. On-chip memory structures, such as register files, caches, and scratch-pads, provide fast and energy efficient access to program and data by reducing the slower and power hungry off-chip accesses. Memory power, therefore, can be reduced by employing techniques to effectively utilize these storage elements.
In this project, three different compiler orchestrated, but hardware-assisted techniques, are proposed that target these on-chip storage elements while being performance neutral: Windowed Register Files , Low Power Code Cache and Partitioned Data Cache
Windowed Register File
Embedded microprocessors commonly employ a 16-bit instruction set design to take advantage of extremely compact code and thus smaller memory footprint. While the efficiency of 16-bit processors is high, the performance of these systems can be problematic. With a 16-bit instruction set, the number of bits to encode source and destination operand specifiers often limits the number of architected registers to a small number (e.g., eight or less). Such a small number of registers often limits performance by forcing a large fraction of program variables/temporaries to be stored in memory. Spilling to memory is required when the number of simultaneously live program variables and temporaries exceeds the register file size. This has a negative effect on power consumption as more burden is placed on the memory system to supply operands each cycle.
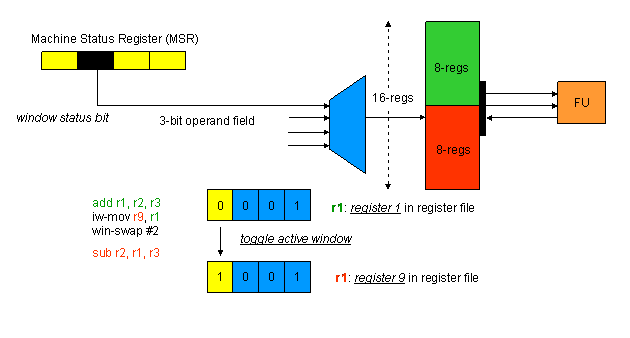
Our approach is to provide a larger number of physical registers than allowed by the instruction set encoding. This approach has been designed and implemented within the low-power, 16-bit WIMS (Wireless Integrated Microsystems) microcontroller. The registers are exposed as a set of register windows in the instruction set. At any point in the execution, only one of the windows is active, thus operand specifiers refer to the registers in the active window. Special instructions are included to activate windows and move data between windows. The goal is to provide the appearance of a large monolithic register file by judiciously employing the register window.
The goal of this project is to allocate virtual registers within a procedure across multiple register windows. Towards this goal, the compiler employs a novel Fiduccia-Mattheyses-based graph partitioning technique. A graph of virtual registers is created and partitioned into window groups. In the graph, each virtual register is a node and edges represent the affinity (the desire to be in the same window) between registers. Spill code is reduced by aggressively assigning virtual registers to different windows, hence exploiting the larger number of physical registers available. However, window maintenance overhead in the form of activating windows (also known as window swap) and moving data between windows (also referred to as inter-window move) can become excessive. Thus, the register partitioning technique attempts to select a point of balance whereby spills are reduced by a large margin at a modest overhead of window maintenance.
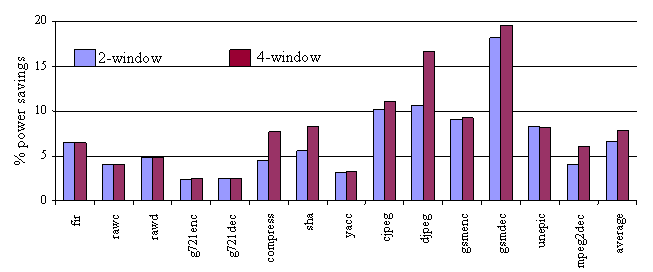
Overall system power savings in scaling to a 2, 4-window configuration w.r.t a 1-window configuration with 8-registers per window on the WIMS microcontroller
Low Power Code Cache
In embedded processors, the instruction fetching subsystem can contribute to a large fraction of the total power dissipated by the processor. For example, instruction fetch contributes 27% in the StrongARM SA-110, and almost 50% for the Motorola MCORE of the total processor power. Intuitively, this makes sense as instruction fetch is one of the most active portions of a processor. Instructions are fetched nearly every cycle, involving one or more memory accesses some of which may be off-chip accesses.
In this work, we use a compiler managed low power code-cache called the Loop Cache (LC). The LC, unlike traditional instruction caches, avoids complex tag comparison logic and thus saves on fetch power. By allocating frequently executed instructions into the software managed LC of relatively small size (128 - 1024 bytes), instruction fetching can be directed from the LC, thus saving on the fetch power. Traditionally, static software schemes have been employed to map the hot regions of the program into the LC. But such schemes break down when a program has multiple important loops that collectively cannot fit in the LC. As a result, only a subset of the loops can be mapped into the LC. Compiler-directed dynamic placement allows the compiler to insert copy instructions into the program to copy blocks of instructions into the LC and redirect instruction fetch to the LC. As a result, the compiler can change the contents of the LC during program execution as it desires by inserting copy instructions at the appropriate locations. Compiler-directed dynamic placement has the potential to combine the benefits of the hardware-based schemes with the low-overhead of the software-based schemes.
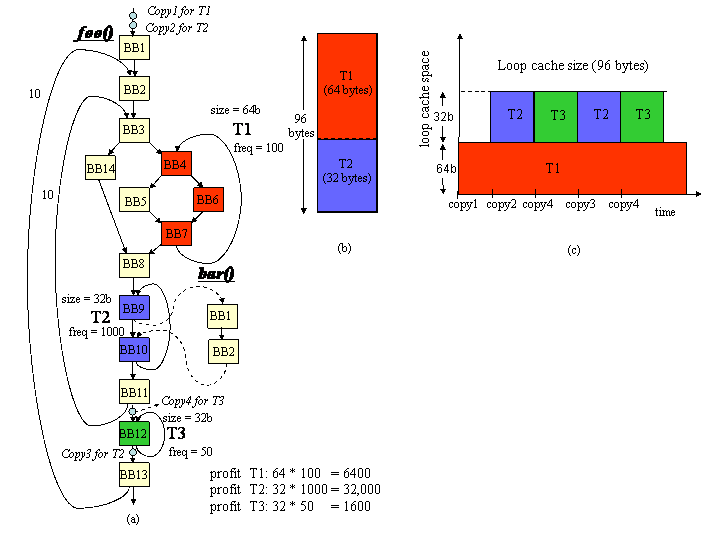
Advantages of dynamic over static loop cache placement. Static scheme can allocate traces T1 and T2, while the dynamic scheme can accommodate T1, T2, and T3.
We propose an inter-procedural analysis technique to identify hot instruction traces to be inserted in the LC. Based on a profile-driven power estimate, the selected traces are then packed into the LC by the compiler, possibly sharing the same space, such that the run-time cost due to copying the traces, is minimized. Through iterative code motion and redundancy elimination, copy instructions are inserted in infrequently executed regions of the code to copy traces into the LC. The approach works with arbitrary control flow and is capable of inserting any code segment into the LC (i.e., not just a loop body).
Iterative inter-procedural copy hoisting and placement example. Figure (a) shows the initial position of the copies (Cs). Figure (b) shows an intermediate step during hoisting while Figure (c) shows the final position of the copies. The live-ranges of the traces are shown next to each figure. Hoisting is done when the live-ranges of traces do not intersect.
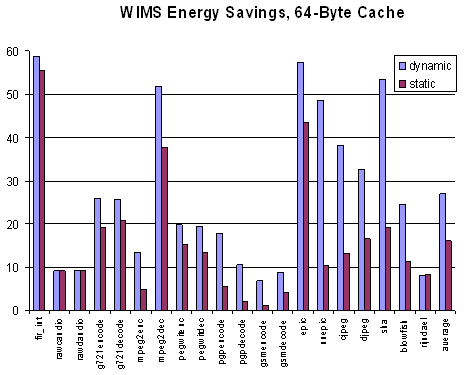
Energy savings for static and dynamic scheme for 64-byte loop cache on the WIMS microcontroller
Partitioned Data Cache
Data caches have been highly successful in bridging the processor-memory performance gap by providing fast access to frequently used data. They also save power by limiting expensive off-chip accesses.
However, the use of caches in embedded domains has been limited due to energy inefficient tag checking and comparison logic. Set-associative caches can achieve a high hit-rate and good performance, but it comes at the expense of energy overhead. Direct-mapped caches remove much of the logic overhead and thus consume much less power per access, but they incur more misses. Studies show that the on-chip memory subsystem, specifically the instruction and data caches, is the highest contributer to the overall system power. For example, caches consume around 40% of the total processor power in the StrongARM 110 and around 16% for the Alpha 21264 processor.
We propose a hardware/software co-managed partitioned cache architecture that attempts to bridge the performance and energy gap between direct and set-associative caches. A partitioned cache consisting of multiple smaller direct-mapped partitions with the same combined size as a unified direct or set-associative cache is employed. Management of these partitions is controlled by the compiler using load/store instruction set extensions. Using a whole program knowledge of the data access patterns, the compiler controls cache lookup and data placement by assigning individual load/store instructions to these partitions.
Architecture
Traditionally, caches are logically organized into ways, where the tag corresponding
to each of the ways are compared in parallel to reduce access cycle time.
The data is read from the matching way. Prior to matching, the
parallel access has to pre-charge and read all the tag
and data arrays, but select only one of the ways
resulting in wasted dynamic energy.
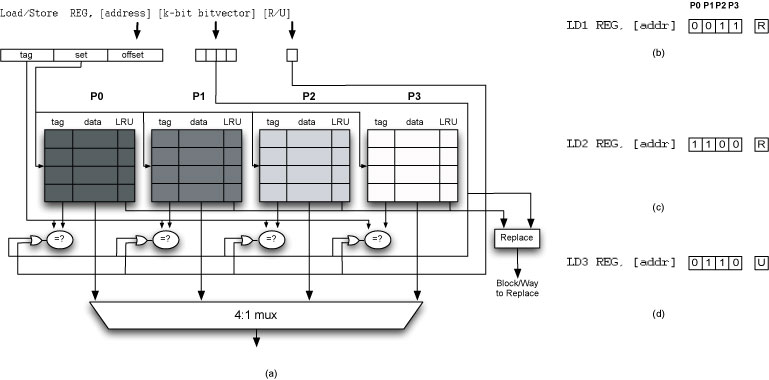
Figure (a) shows a 4-way set-associative cache. Each way is treated as a software-controlled cache partition. We conceptually extend the load/store instructions with additional operand fields. For a k-partitioned cache, a k bit-vector immediate field is used to denote the partition (i.e., way) to which the instruction is assigned. LD 1 in Figure (b) is assigned to partitions 2 and 3. Similarly, LD 2 in Figure (c) is assigned to partitions 0 and 1, and LD 3 Figure (d) in is assigned to partitions 1 and 2.
Cache Replacement: On a miss in the cache, the ways specified by the bit-vector are considered for replacement. This allows the compiler control over the replacement decisions among the ways in a set. The flexibility of the underlying hardware allows the compiler to treat individual loads as needing only a single way up to all the ways of the cache, based on its access characteristics.
Cache Lookup: On a cache access, all ways that could possibly include
the cache block must be probed. This is required to
avoid any coherency and duplication of cache blocks. If two memory references
sharing the same set of data objects are placed in different partitions,
then all such partitions have to be checked for the presence of
the data. The lookup is accomplished using the
replacement bit-vector and a single extra bit-field,
called the
Advantages : This software-guided partitioned cache architecture has the following advantages
- A smaller direct-mapped cache is more power efficient than either a unified direct-mapped or a set-associative cache, as the data and tag arrays are smaller. The software decides what partitions are activated, thus eliminating redundant tag/data array accesses to reduce power.
- By managing the placement of data using the memory reference instructions, the compiler can enforce a better replacement policy. For example, data items that are accessed with a high degree of temporal locality can be placed in different partitions so as to avoid conflicts. But references that are separated in time or whose live-ranges do not intersect can be made to share the same partition. Thus, this data orchestration can help reduce conflict misses.
Relevant Publications
Page last modified January 22, 2016.