
Customizing a processor's instruction set exploits the observation that recurring subgraphs frequently exist in the dataflow graphs (DFG) of applications. By implementing these frequently occurring subgraphs in hardware as instructions, performance improves, code size decreases, and energy consumption is reduced.
We believe the process of selecting instruction set extensions should be automated, since the number of potential subgraphs in an application is too large for a person to process (it grows exponentially with the size of the DFG). For example, the DFG in the figure below is 1/4 of one basic block for the encryption application Blowfish. The black squares in this figure represent operations, and the red lines are dataflow edges. There are many subgraphs, some of which are highlighted.
Dataflow graph from the application Blowfish
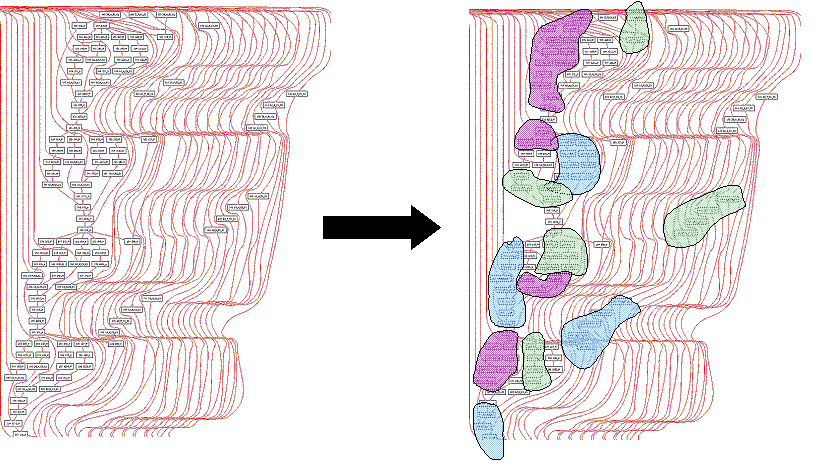
The CCCP group has developed tools to automatically select appropriate instruction set extensions for a given application, or set of applications. We have also developed compiler algorithms to utilize the instruction set extensions in applications that were not examined by the selection tools.
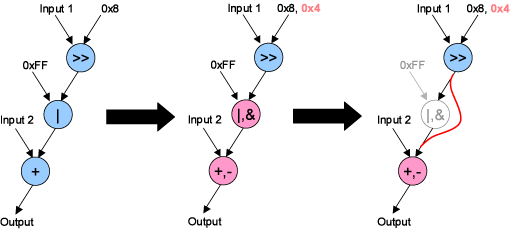
Perhaps more importantly, we've developed techniques to cost-effectively generalize these instructions to make them more applicable across a range of applications. Generalization is key, since we want to make the custom instructions usable even if the application changes because of bug fixes, or slight algorithmic changes.
One technique for subgraph generalization, we term wildcards. Wildcards take advantage of the fact that some operations are similar, or can be added to nodes for very little additional cost. For example, add and subtract are very similar, so subtract could be cheaply added to the bottom node in the example below. The new unit could then execute shift-or-subtract in addition to shift-or-add.
A second technique for subgraph generalization, we term subsumed subgraphs. This arose from the observation that each each node has an identity input, and values can pass through those nodes unchanged using this identity. This allows one to execute a shift-add on the unit below, for example.
Generalization techniques for instruction set extensions.
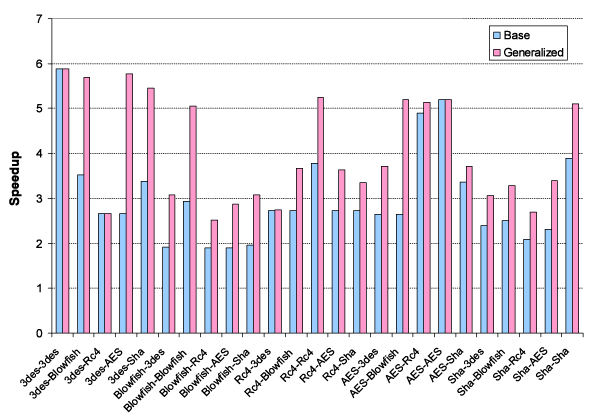
The CCCP group has taken these techniques and implemented them in ARM's OptimoDE design framework. Some results of this are presented below. Two applications are listed for each point along the X-axis signifying the application being run and the application the instruction set extensions were designed for, respectively. Speedup is relative to an ARM 10 processor.
Clearly, instruction set extensions are powerful, and the generalization techniques improve their utilization across an entire domain of applications.
Performance improvement in the encryption domain.
Relevant Publications
Page last modified January 22, 2016.